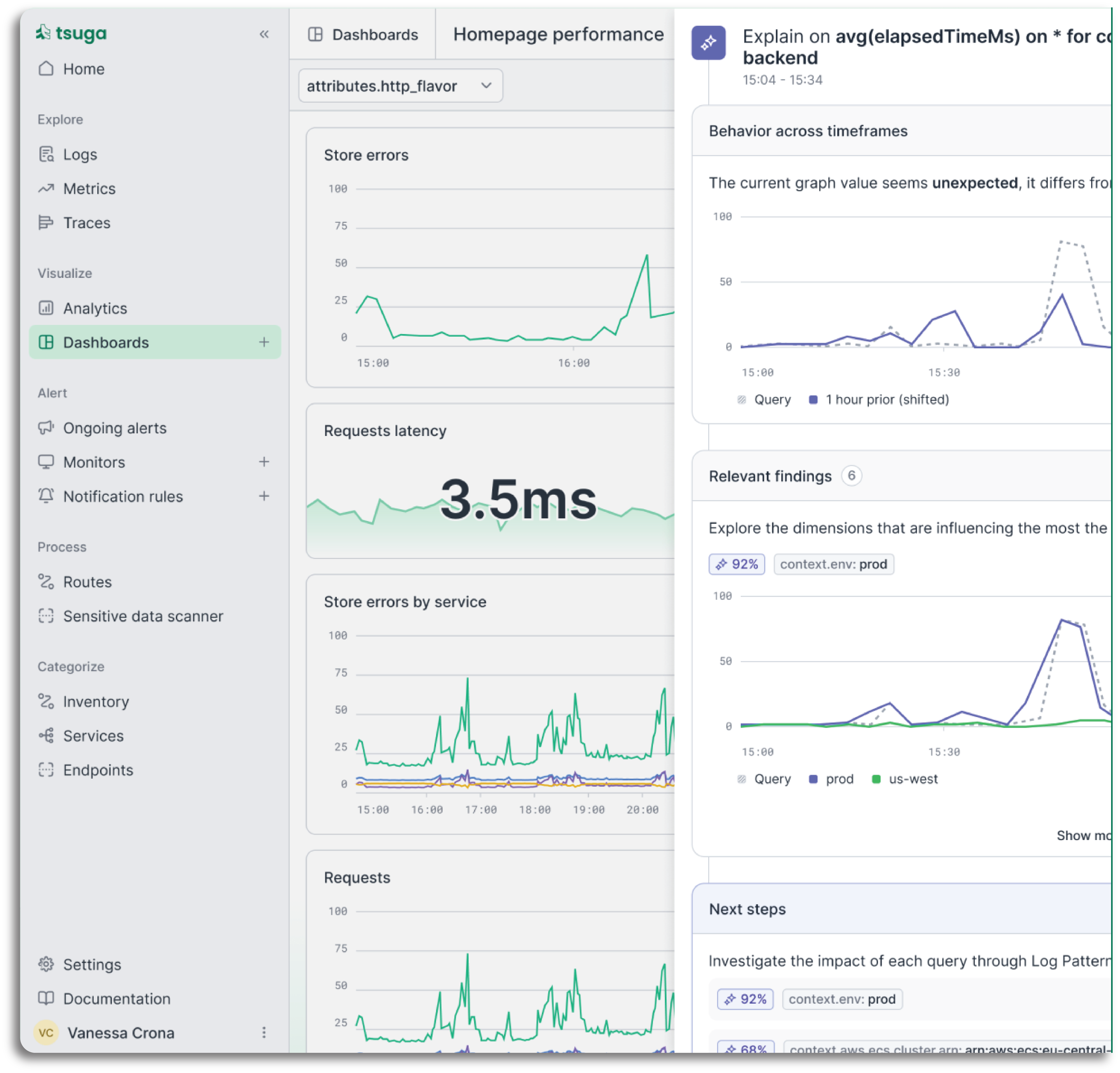
You pay for software, not a markup on your own infrastructure
Traditional platforms ingest your telemetry into their cloud, then charge you for accessing your own data. Storage and compute hit their bill, marked up and passed on to you. With Tsuga, the engine runs on your EC2 instances and writes to your S3 buckets. Those costs hit your AWS bill directly. We charge for the software layer we manage.