Why AI-assisted RCA changes the requirements of the observability stack
Antoine Dussault
AI-assisted root cause analysis fails when the observability stack underneath it wasn't built for autonomous systems. Learn why RCA is a context architecture problem, not an LLM problem.
 Root cause analysis has always been a race against time, and for most engineering teams the bottleneck has never really been analytical ability. It has been context.
Root cause analysis has always been a race against time, and for most engineering teams the bottleneck has never really been analytical ability. It has been context.
An alert fires and the investigation that follows is less a coherent inquiry than an archaeology project: digging through traces in one tool, logs in another, deployment history somewhere else, Kubernetes state in a fourth place that nobody fully owns. The time it takes to resolve incidents is driven by how quickly a team is able to reconstruct the causal chain behind a failure.
AI agents are now taking on that same investigation work, and they are running into exactly the same problem.
The promise is enticing. An autonomous RCA agent gets paged, works through telemetry, reconstructs what changed and why the failure propagated, and surfaces a plausible root cause all before a human engineer has even opened their laptop.
But the quality of that investigation is entirely determined by the observability underneath it. If the telemetry it queries is incomplete, heavily sampled or difficult to query programmatically, the agent will either miss the root cause entirely or produce a confident-sounding answer built on incomplete evidence.
The industry often frames AI-assisted RCA as an LLM problem. In practice, it is primarily a context architecture problem.
Root cause analysis is fundamentally a context reconstruction problem
What makes distributed systems’ root cause analysis genuinely hard is not locating the error. Modern observability systems are already very good at surfacing symptoms: latency spikes, elevated error rates, unhealthy pods, failed requests.
The hard part is tracing the connection between the error and its origin.
A runtime exception in a downstream service does not announce itself at the frontend endpoint where the monitor fires. It propagates through layers until the symptom that triggers the alert bears only an indirect relationship to the cause.
A reliable investigation requires:
Traces showing the full cascade across services
Logs containing the explicit error and stack trace
Metrics revealing behavioral changes over time
Deployment history showing what changed
Kubernetes events describing infrastructure state transitions
Cloud assets inventory identifying affected resources and their relationships
Source code and ownership context explaining operational intent
This was already true when humans performed investigations manually, it becomes even more important when the investigator is an autonomous system. The efficiency of RCA has always depended on context architecture.
Most observability systems were designed for human investigation workflows
Most observability platforms were built around a specific assumption: humans are the consumer.
That assumption shaped the architecture of these platforms:
Dashboards instead of machine-oriented data retrieval
Aggregation over predefined dimensions instead of exhaustive context
Low-retention, sampled telemetry instead of long-lived and high-fidelity investigation data
Sparse interactive querying instead of continuous, programmatic retrieval
Expensive queries intended for occasional human use
Those tradeoffs made sense: human engineers do not consume tens of millions of telemetry rows directly. Platforms were and are still optimized for engineers navigating through dashboards, aggregates, heuristics and selective drill-downs. Humans compensate for the sampled, missing context with intuition, operational experience, and institutional knowledge.
Autonomous RCA systems behave differently.
They need full context rather than sampled snapshots, queried at machine speed. They also depend on interfaces that return the right information at the right level of granularity without exhausting their context window on noise that a human would have filtered out instinctively.
The query workload and query interface requirements fundamentally change.
Many observability systems still assume humans are both the main consumer of observability data and the query bottleneck. That assumption no longer holds. Autonomous systems are now becoming the query workload itself.
This changes the requirements of the observability stack.
1. Structured context becomes critical
Human engineers mentally reconstruct relationships between traces, logs, metrics, deployments, infrastructure state, source code and ownership.
Agents cannot rely on intuition to bridge disconnected systems.
They require explicit, machine-readable relationships between telemetry types, application and infrastructure changes down to code versions. Without structured context, agents either over-fetch large amounts of irrelevant telemetry or draw conclusions from incomplete evidence. This also increases hallucination risk, as agents must infer relationships that are not explicitly represented.
2. Query availability becomes part of investigation quality
Traditional observability systems optimise for cost control and sparse human interactions. Rate limits and aggressive sampling are tolerable when the product provides some well-defined aggregations to compensate and when investigations involve a small number of targeted queries through a UI.
Autonomous investigations work differently.
Agents perform recursive querying, with broad retrieval patterns and repeated context expansion across large pools of data, for instance via automated one-off scripts. Restricting telemetry access through aggressive query limits, incomplete retention or prohibitive cost directly reduces investigation quality. Sampling becomes a much bigger problem when the consumer is an autonomous reasoning system attempting to reconstruct a causal chain of events and changes.
3. RCA requires context beyond telemetry
Another structural issue becomes visible as soon as you try to make agent-driven investigation genuinely useful in enterprise environments. The richest investigation context often exists outside of the observability platform itself: it is the source code, the git history, deployment pipelines, runbooks, prior incident records and organizational ownership structure. Human engineers naturally bridge these systems during investigations. Their experience acts as the glue between fragmented operational tools.
Autonomous RCA systems need more than just telemetry.
They either require the platform itself to provide that contextual unification or need to live in a place where it can access that data. For instance, a cloud-hosted agent can query a vendor's data plane, but connecting it to internal repositories and knowledge sources is either impractical or introduces data sovereignty concerns that regulated industries and large enterprises cannot accept. The result is an agent reasoning from telemetry alone while the most relevant context sits out of reach.
Building observability systems for autonomous investigation
AI-assisted RCA fundamentally changes the requirements of the observability stack. The architecture that actually works starts from a different set of assumptions.
The platform needs to provide:
Unified access to logs, traces, metrics, infrastructure state, and deployment context
Structured interfaces and retrieval patterns designed for machine consumption
High query availability without restrictive rate limiting
Direct access to internal context without compromising governance or security
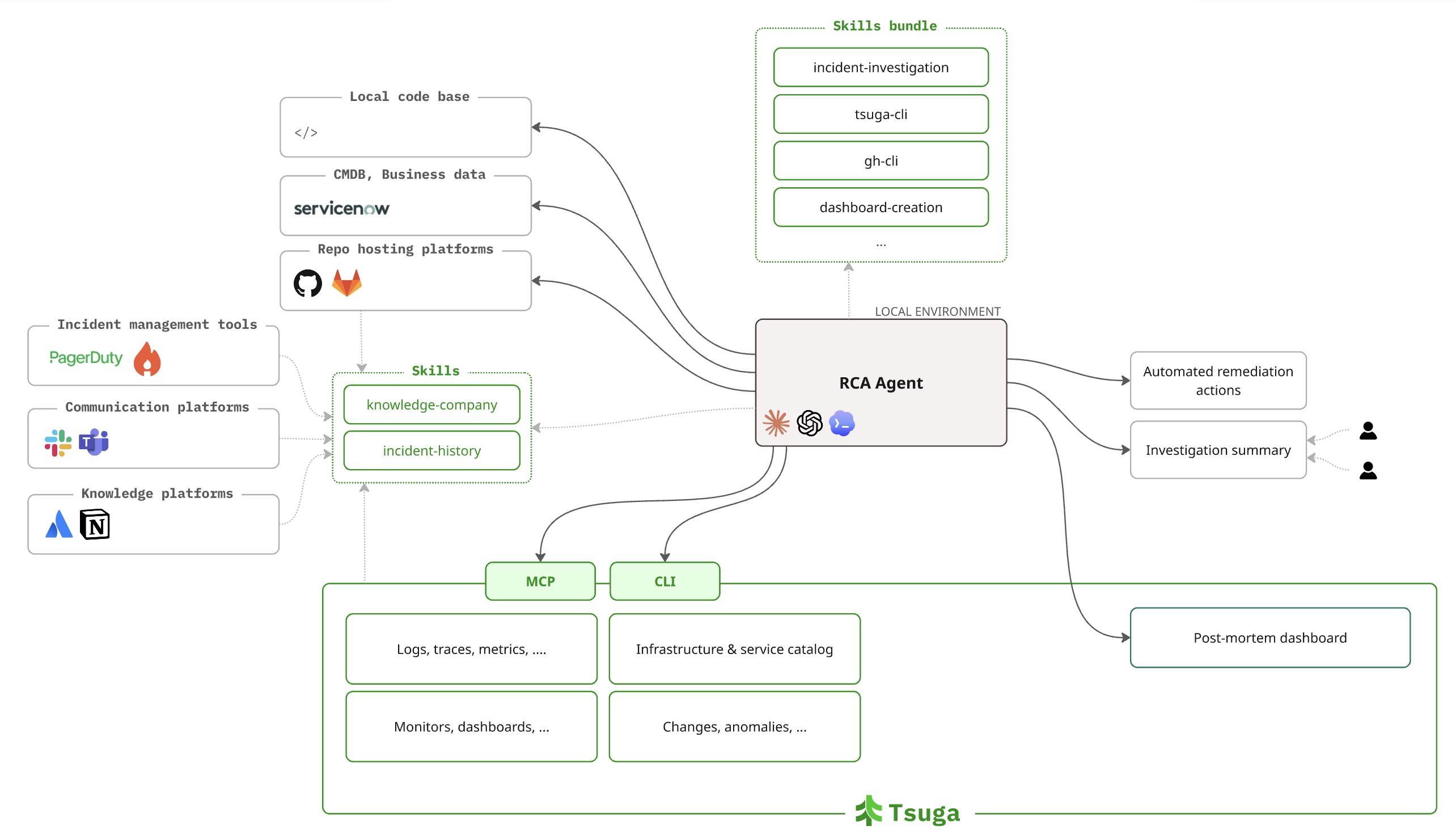
This is the approach we have taken at Tsuga.
Tsuga data plane lives in your environment, under your keys, within your network boundary. The platform unifies logs, traces, metrics, deployments, infrastructure changes as well as assets built on top of it (alerts, SLOs, dashboards). It also exposes interfaces designed for AI-assisted investigation workflows, including MCP and CLI access patterns that support exhaustive retrieval and recursive exploration, without rate limits.
Tsuga does not sell you yet another RCA Agent: it enables your agents to operate directly on your systems without production telemetry leaving your infrastructure and without vendor margin on top of LLM costs. Your agents run locally, with access to your codebase, your internal knowledge sources, and your deployment context, because that combination is what makes the difference between a correct root cause and a confident-sounding approximation. In this context, Tsuga provides structured, AI-native interfaces that understand your entity graph, track changes across infrastructure and application layers, without opinions about what is relevant to surface during an investigation and what to prune. The agent reasons across a coherent picture rather than assembling one from scratch on every run.
With that foundation in place, the investigation changes character entirely. The agent starts from the alert, works through traces to identify the cascade, checks logs for the explicit error, uses span metrics to pinpoint the version change, and confirms the deployment event through Kubernetes state. With all of this research grounded in actual operational context assembled from internal knowledge bases and incident history, to build a picture of the causal chain of events, suggest proper remediation options and build a business impact assessment. It then publishes that investigation as a structured object, in Tsuga, that the team can review, act on, and build from.
The agent does not replace the engineer. The goal is to compress the distance between an alert firing and the team having a clear, evidence-based understanding of what changed, why the failure propagated, and what needs to happen next.
But that only works when the underlying observability platform was designed to serve autonomous reasoning systems rather than retrofitted for them afterward.
To see what AI-native observability with integrated RCA workflows look like in practice, request a demo of Tsuga.
AI-assisted RCA is ultimately a context problem. Seeing everything should be economically viable. Rationing context is not an investigation strategy.